

Single points of failure pose significant challenges because they introduce vulnerabilities that can compromise the reliability and resilience of systems. Identifying and mitigating these weaknesses is essential for building robust, scalable architectures.
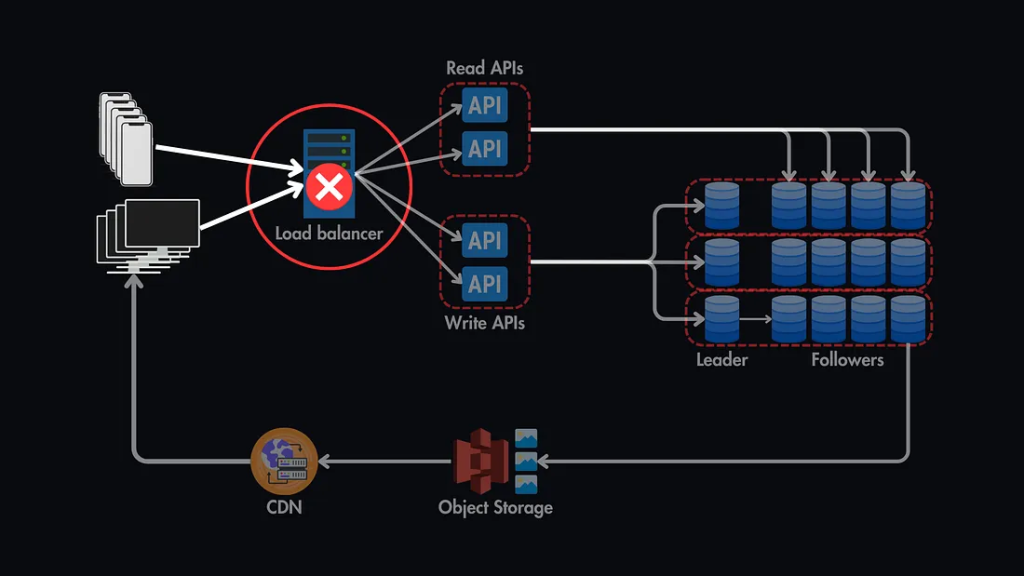
By addressing SPOFs, you can:
- Enhance Reliability: Avoid situations where a single failure disrupts the entire system, preventing business losses and user dissatisfaction.
- Improve Scalability: Systems with SPOFs often struggle to grow, as each additional component increases risk.
- Boost Security: A single vulnerable entry point simplifies an attacker’s job of compromising the system.
Common Single Points of Failure in Systems 🤔
Understanding typical SPOFs can help in designing systems that are resilient. Here are some common examples:
- Databases: Databases often act as the backbone of applications. If hosted on a single server without replication, any failure can take the entire application offline.
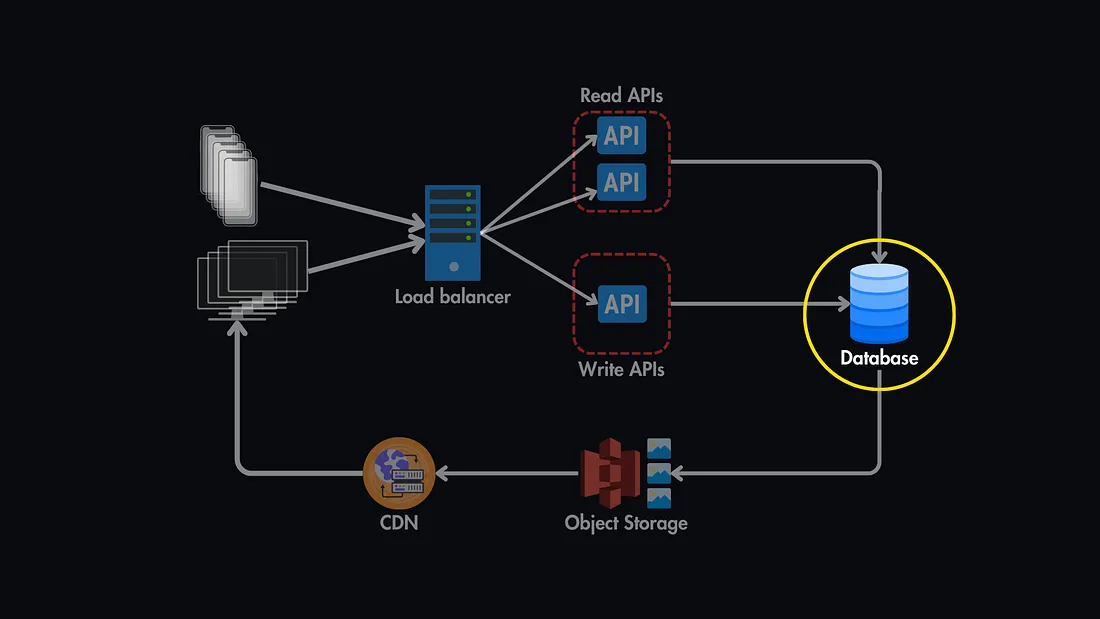
- Load Balancers: Load balancers are designed to distribute traffic and enhance reliability. However, a single load balancer can itself become a SPOF if not duplicated.

- Application Servers: Hosting applications on a single server creates a significant vulnerability, as server failure leads to downtime for the entire service.
- Network Connections: A single internet link can become a SPOF, making the system inaccessible to users if it goes down.
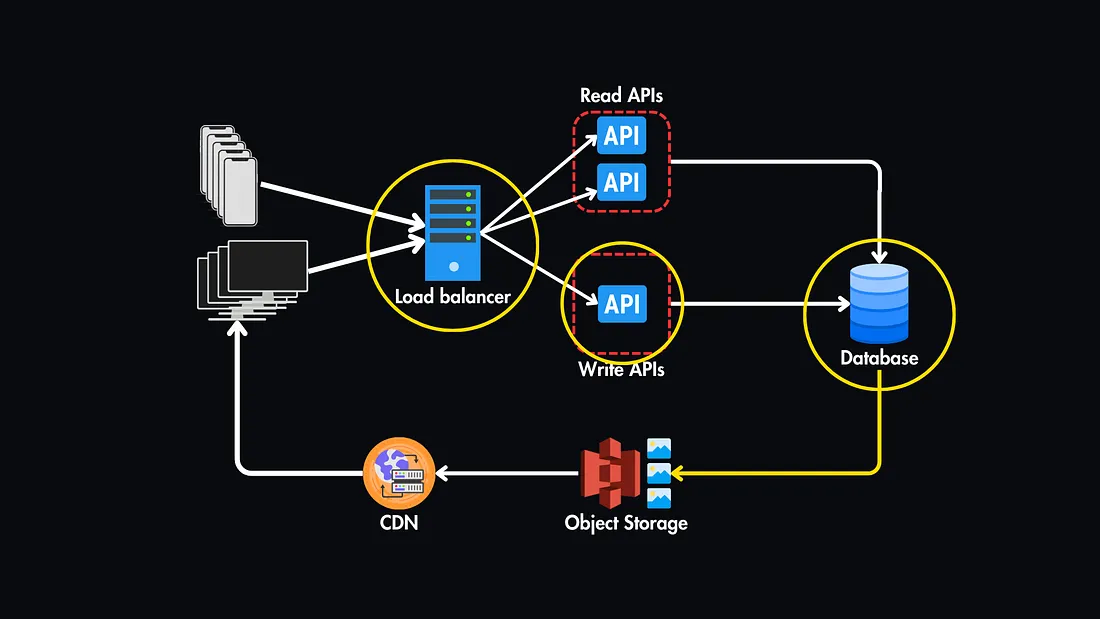
💡Strategies to Eliminate Single Points of Failure
To build systems that are resilient and scalable, it’s essential to address and mitigate SPOFs. Below are key strategies:
1. Redundancy
Duplicating critical components is one of the most effective ways to eliminate SPOFs. Multiple instances of databases, load balancers, and servers ensure that if one fails, others can continue operating.
Example: Implementing multiple database replicas ensures continuous operation even if one instance goes offline. 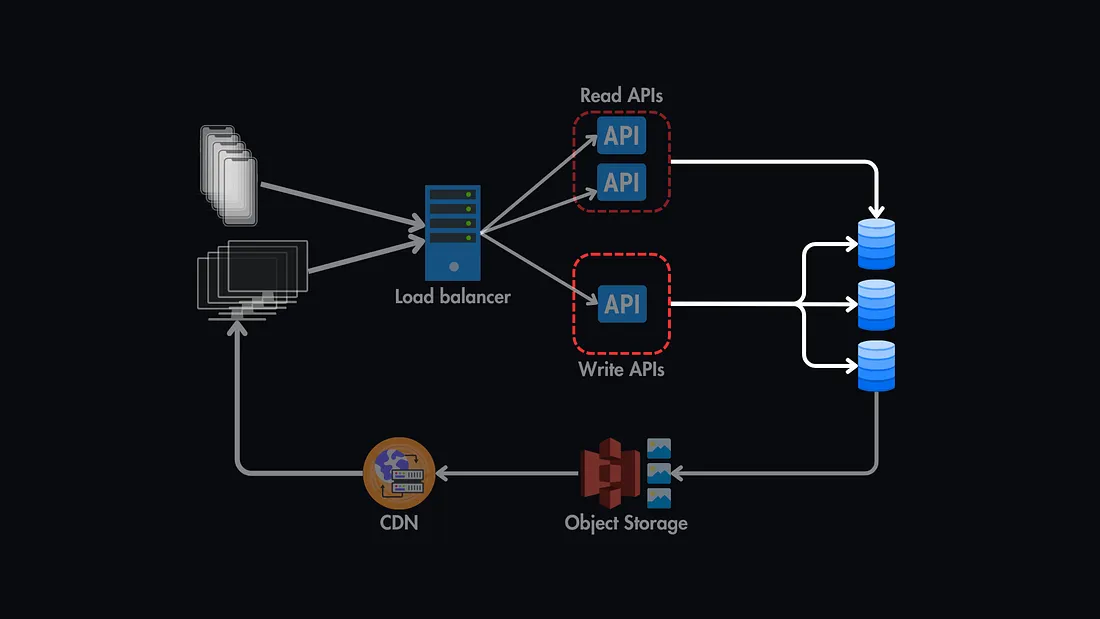
2. Failover Mechanisms
Failover mechanisms allow backup components to automatically take over if a primary system fails, minimizing downtime.
Example: Setting up failover for API servers ensures a standby server takes over immediately if the primary server encounters an issue. 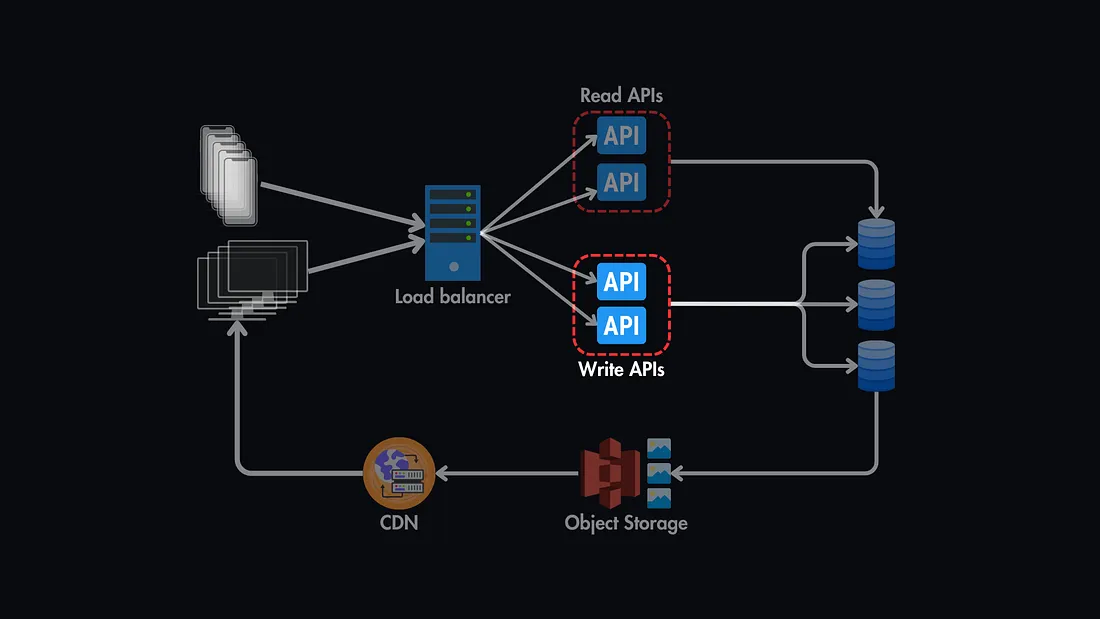
3. Load Balancing
To avoid making the load balancer itself a SPOF, deploy multiple load balancers in a failover configuration.
Example: In case one load balancer fails, traffic is seamlessly redirected through another. 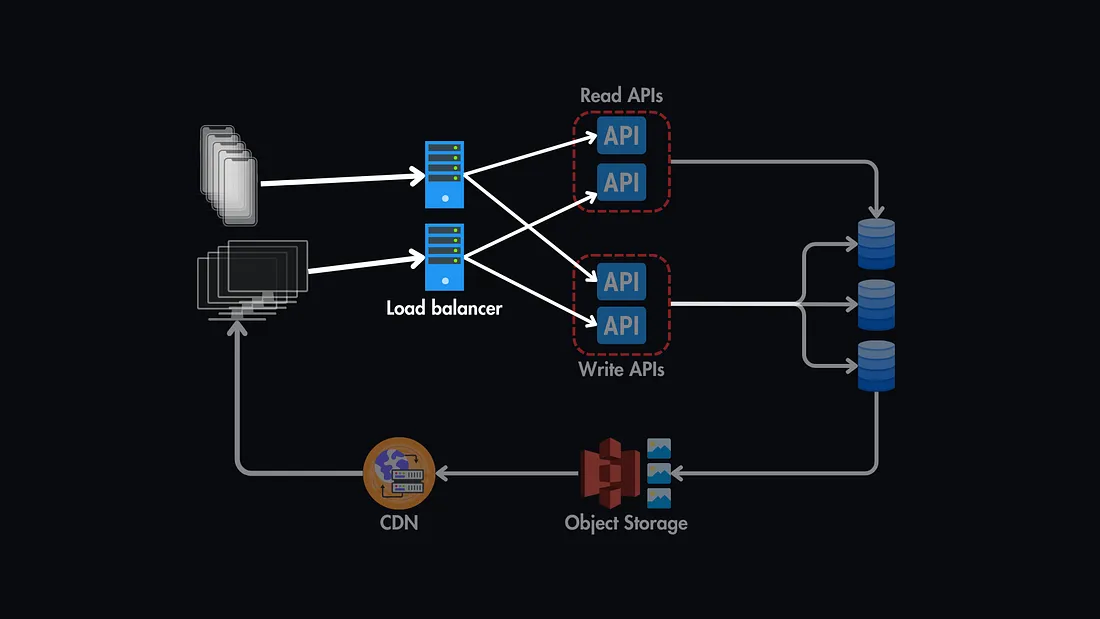
4. Geographic Distribution
For globally distributed systems, hosting servers in multiple regions reduces the risk of location-specific failures.
Example: Using a Content Delivery Network (CDN) distributes static assets across the globe, minimizing reliance on any single server.
5. Monitoring and Alerts
Continuous monitoring of systems with proactive alerts can detect failures early, enabling swift corrective action.
Example: Deploy monitoring tools to track system health and set up alerts for performance degradation or outages. 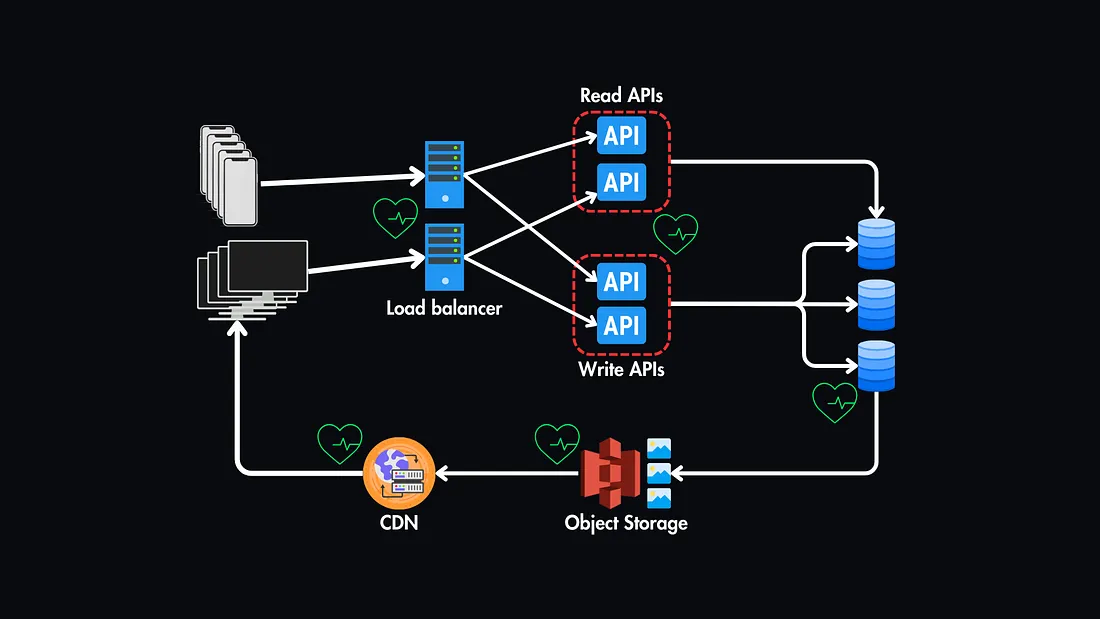
Even experienced system designers can fall into certain traps when mitigating SPOFs. Here are a few pitfalls to avoid:
- Overlooking Load Balancers: Adding a single load balancer as a solution can introduce a new SPOF.
- Neglecting Failover Testing: Backups and failover mechanisms are only effective if tested regularly.
- Ignoring Monitoring: Without monitoring, redundancy and failover solutions may fail unnoticed, undermining their purpose.
In system design, eliminating SPOFs is not just a technical necessity but a business imperative. By identifying and mitigating SPOFs, organizations can enhance system resilience, ensure continuous service delivery, and maintain customer trust. Adopting strategies such as redundancy, failover mechanisms, and regular testing can pave the way for robust, fault-tolerant systems.
We are happy to help 🤝


